


Similar Websites
Explore more handpicked websites that might interest you. Each showcases unique design and functionality.

Realtime Robotics
Artificial Intelligence
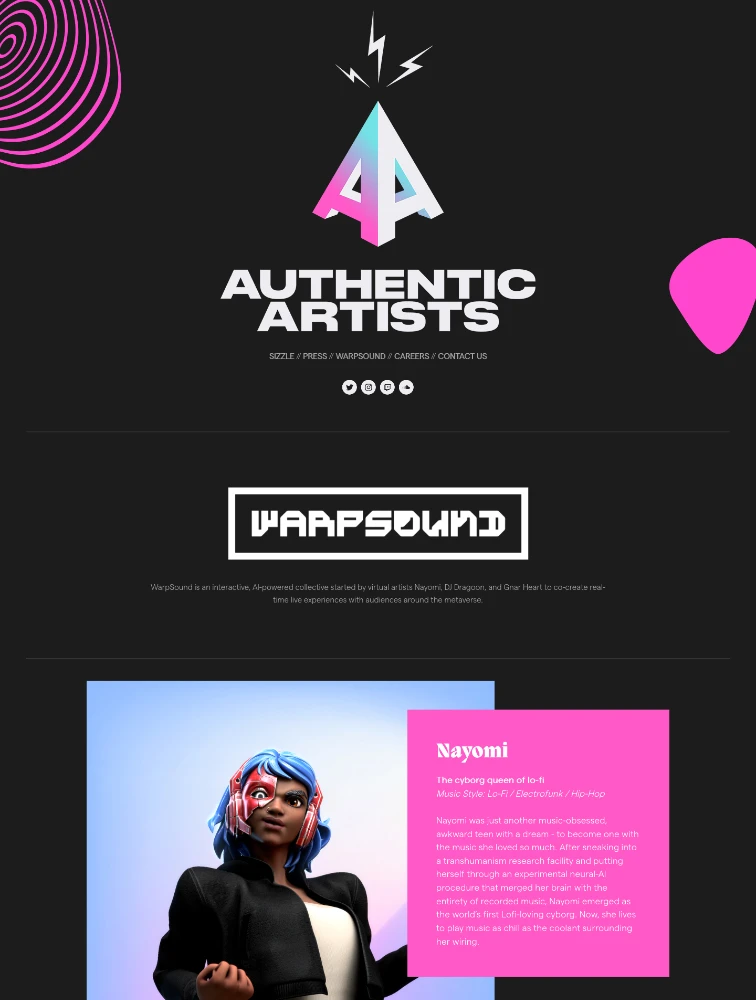
Authentic Artists
Artificial Intelligence

 Binaryblocks
Binaryblocks
Illustration

 Cash App
Cash App
App

Dala
Artificial Intelligence

 Digilab
Digilab
Corporate

Scout
3D Websites

Ghost Locomotion
Artificial Intelligence